Subscribe to our newsletter
Thanks you for subscription!
Oops! Something went wrong while submitting the form.


LLaMA 2.0 was released last week — setting the benchmark for the best open source (OS) language model. Here’s a guide on how you can try it out on your local hardware and fine-tune it on your data and use-cases.
TitanML has three modules, two of which are perfect for generative language models, Titan Takeoff and Titan Train — in this blog we will use both of them for the inference and the fine-tuning of this awesome OS model!
Start by installing the Titan platform CLI program. Once the CLI program is installed, login by running iris login. You’ll be presented with instructions to navigate to a login page in your browser. Log in or sign up on that page, and then return to your terminal to start playing with the Titan platform!|

Last week we announced our Titan Takeoff Inference Server. This allows users to run super fast and optimised local inference of large generative language models — think of it like HF inference endpoints but hyper-optimised and run locally. Here’s how to get it running for LLaMA 2.0…
To get access to the LLaMA weights, fill out the form here. Then, navigate to the Hugging Face page for the model you want to deploy, for example llama-7b. Fill out the form on that page, with the same email as you used on the Meta page. Meta and Hugging Face will send you an email when you have access to the weights, and when Hugging Face has connected to Meta and has registered your access. Once those emails have come through, you should be ready to deploy!
First, create a Hugging Face API token in the Hugging Face settings. Then, export the following environment variable, with the value of the token you have just created:
export HF_AUTH_TOKEN=...
Make sure to replace the ... with the actual token, and put it in single quotes if it contains special characters. After doing so, navigate to a LLaMA model of a size that will fit on your hardware. To run optimization of the LLaMa-7b and LLaMa-13b models, you'll need around 64GB of RAM.
The models will inference in significantly less memory for example: as a rule of thumb, you need about 2x the model size (in billions) in RAM or GPU memory (in GB) to run inference. For now, this requires transfering the optimised weights — contact us on our discord, or via email for more information.
You can launch the server with the following command:
iris takeoff --model="meta-llama/Llama-2-7b-hf" --hf-auth-token $HF_AUTH_TOKEN --port 8000
If you have a GPU, run with the following command:
iris takeoff --model="meta-llama/Llama-2-7b-hf" --device cuda --hf-auth-token $HF_AUTH_TOKEN --port 8000
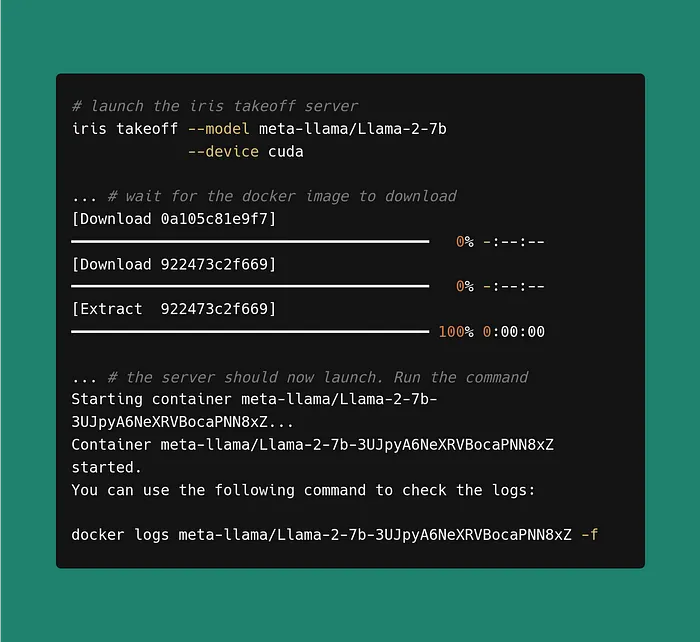
Internally, this will download the model weights, optimise the model, and then launch the server. This process outputs a Docker command to view the server logs. You can execute it as follows:

Once optimisation is complete, the server should spin up.
To call the server directly, use the following command:
curl -X POST http://localhost:8000/generate_stream -N -H "Content-Type: application/json" -d '{"text":"List 3 things to do in London"}'
The response from the model should stream back to the screen.
You can explore the API specification at http://localhost:8000/docs. We also provide two demo applications for you to experiment with: a chatbot and an OpenAI style playground. You can access these at http://localhost:8000/demos/chat and http://localhost:8000/demos/playground, respectively.
Once your model is up and running in the iris takeoff server, you can interact with it in various ways.
The iris executable includes a command line chat client for quickly testing the model. To try it, run
iris takeoff --infer
To access the chat interface for a model deployed using the Titan Takeoff Inference Server, navigate to http://localhost:8000/demos/chat Here you can chat with your models, and test their conversational capabilities. To tweak the generation settings, like the prepended prompt, the temperature, and more, click the settings icon.

To access the playground for a model deployed using the Titan Takeoff Inference Server, navigate to http://localhost:8000/demos/playground Here you can enter freeform text, and see what the model thinks is the best completion. It's a good place for generating content using LLaMA models, and editing on the fly.

If the general LLaMA models don’t achieve the performance you need, the next best step is to fine-tune them on your data. In this section, we’ll show you how easy it is with the TitanML platform to make this a reality.
To start a LLaMA training job, run the following command. We’ve used the tiny_shakespeare dataset for this example. The tiny_shakespeare dataset is a single dataset with the entirety of Shakespeare’s work.

Navigate to the http://app.titanml.co dashboard to see the progress of your training job.
Once the training job has finished, you will see the performance of the training job, and metrics on how training performed. You can download the optimised model by clicking on the model on the experiments page and then get it running through the Titan Takeoff Inference Server.
All of this is totally free through our beta for non-production use cases, so please do try it out and have fun experimenting — we can’t wait to see what you’ll build!
For full docs: https://titanml.gitbook.io/iris-documentation/getting-started
Join the community: https://discord.gg/PBQxFSFc
TitanML enables machine learning teams to effortlessly and efficiently deploy large language models (LLMs). Their flagship product, the Titan Takeoff Inference Server is already supercharging the deployments of a number of ML teams.
Founded by Dr. James Dborin, Dr. Fergus Finn and Meryem Arik, and backed by key industry partners including AWS and Intel, TitanML is a team of dedicated deep learning engineers on a mission to supercharge the adoption of enterprise AI.


We work with enterprises at every stage of their self-hosting journey - whether you're deploying your first model in an on-prem environment or scaling dozens of fine-tuned, domain-specific models across a hybrid, multi-cloud setup. Doubleword is here to help you do it faster, easier, and with confidence.
