Subscribe to our newsletter
Thanks you for subscription!
Oops! Something went wrong while submitting the form.


The race to ship AI features has turned GPUs into prized real estate. Every millisecond and micro-dollar count when you’re serving interactive agents or reasoning systems at scale. One understudied use case are workloads that don’t mind waiting if it means their tokens get cheaper. This post shares early lessons from building an inference stack optimized for those batched, patience-friendly jobs - and why non-obvious GPUs might be the unsung heroes of the batching world.
Batched workloads are applications which aren’t latency sensitive, but the scale of the workload means they are cost sensitive.
- Use cases: synthetic data generation, migrating vector embeddings, processing document dumps.
- Existing Solutions: most API providers already sell discounted batched tiers - often 50% off in exchange for 24-hour SLAs.
- Request Smoothing: batching lets providers smooth demand spikes so latency-sensitive flows (ChatGPT, copilots) don’t get starved.
Teams generally reach for one of three levers:
1. Hardware prioritization
Assign “low-priority” queues inside a GPU fleet so real-time workloads can preempt batched jobs. Internal chargeback models make it practical to price these queues lower.
2. Spot instances
Accept occasional interruptions and wait for GPUs to appear on the spot market. Delivering within SLA now depends on smart queuing and fast model spin-up.
3. Batch-first stack (the path we’re exploring today)
Rebuild the inference stack itself for batched workloads. This is where we can play offense instead of just trading reliability for price.
LLM inference has two distinct phases:
- Prefill: compute-heavy reading of the prompt.
- Decode: memory-bandwidth-heavy token generation.
Different GPU families favour these phases differently:
- Flop-rich: NVIDIA L4, L40 - great when prefills dominate.
- Bandwidth-rich: RTX 4090/5090 - shine on decode-heavy loops, as well as data centre GPUs like A100s and A40s.
Received wisdom says each new GPU generation lowers cost per token because everything - flops, bandwidth, interconnects - ramps together. That’s true for low-latency, high-throughput chatbot workloads. It’s not universally true once you’re willing to wait.
To quantify the trade-offs, we benchmarked a tiny model (Qwen3-0.6B) purely to illustrate the idea. The conclusions extend to bigger models when workloads are decode-heavy.
Raw GPU Economics

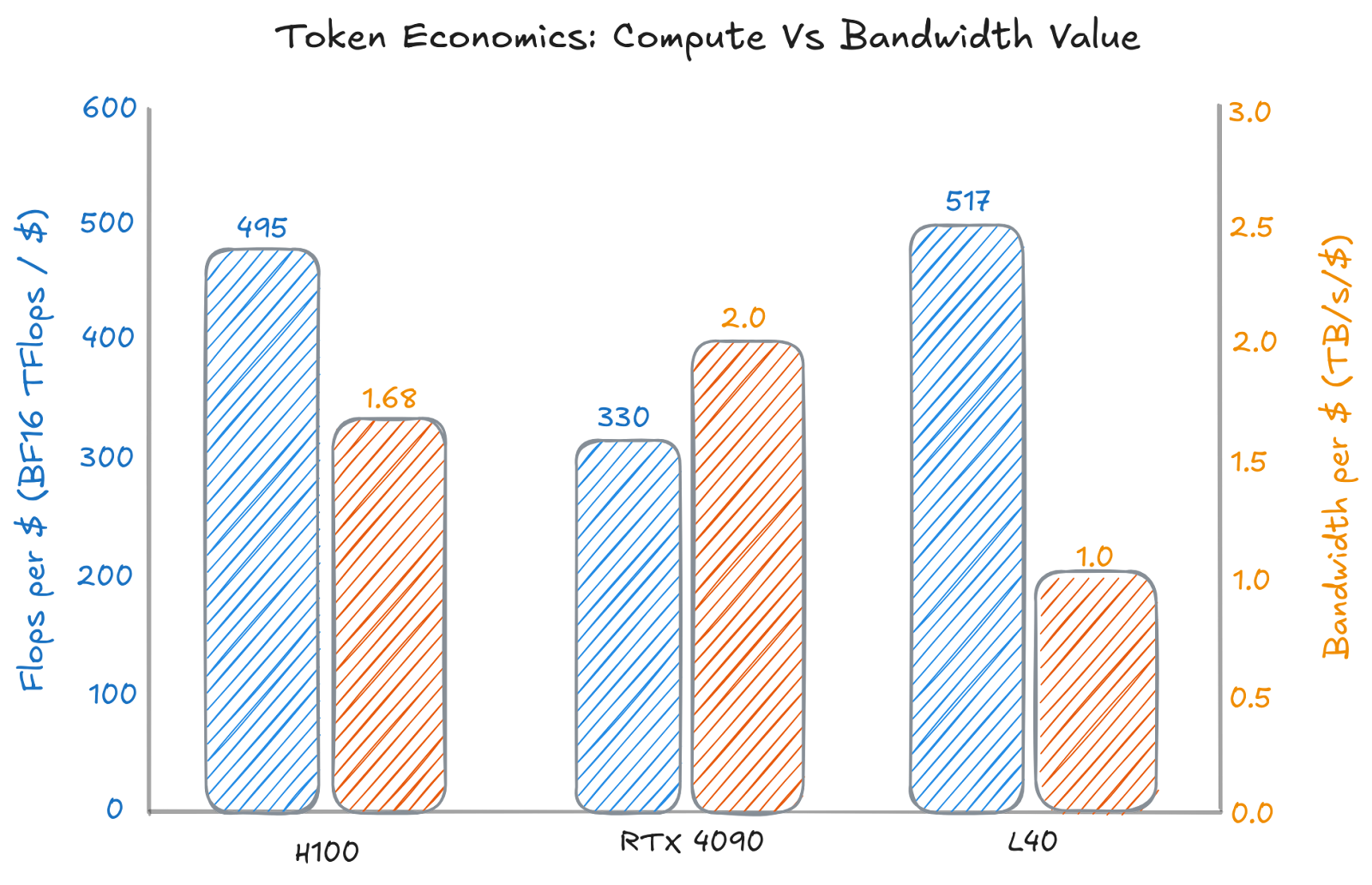
H100 dominates in raw performance and interconnect support (NVLink), which is why it’s the default for latency-bound inference. But the 4090 beats it on bandwidth per dollar - a key lever for decode-heavy batching.
Workload Profile
- Input sequence length (ISL): 512
- Output sequence length (OSL): 1024
This is a marginally decode-heavy workload. Workloads like agents or reasoning models can have far more decode-skewed generation profiles.
If prefills dominated, the tables would turn and flops/$ GPUs like the L40 would be more attractive.
Latency vs. Throughput Results
The raw economics already hinted at the story: an H100 buys you more absolute performance, while each dollar spent on a 4090 buys more memory bandwidth. When we run the experiments, the numbers behave exactly that way.
Single-request latency.
The H100 wins outright at 2.0 seconds per request. With higher flops *and* higher absolute bandwidth, it chews through a decode-heavy prompt faster. The 4×4090 rig trails at 2.3 seconds - a 15% hit that mirrors the deficit we expected from the spec sheet. Although our 4x4090 has more Bandwidth in the aggregate, a single request in the data parallel setup only sees the lower Bandwidth and Flops of a single GPU.
Throughput under load.
Next we send to both setups 500 concurrent requests and normalize the spend (4×4090s cost within a cent of 1×H100 per hour). This is where bandwidth-per-dollar shows up: the consumer stack pushes 23.6k decode tokens per second versus 13.8k on the H100 box. Translated into what you could charge to break even on the GPU spend, the 4090 cluster lands at $0.024 per million output tokens, compared with $0.039 for the H100.
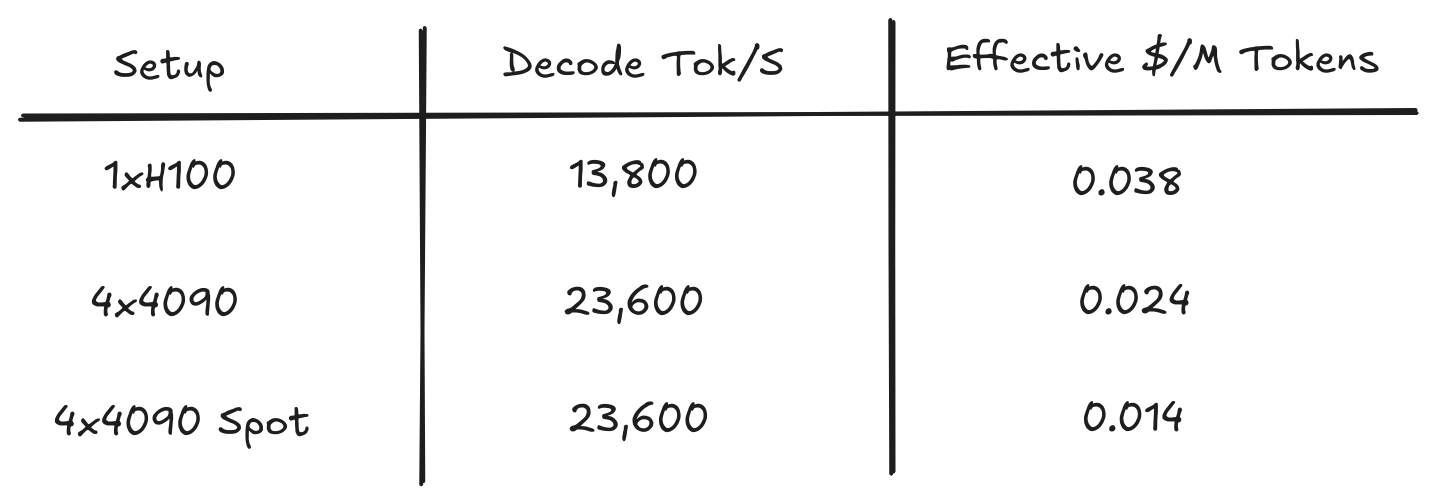
Because this benchmark is decode-heavy, charging only on output tokens fairly represents how customers feel the bill. Prefill-heavy workloads would tilt the economics back toward flop-rich GPUs, like L40S cards.
Spot pricing doubles down on this and delivers cheaper tokens still. Using spot instances would introduce even higher tail latencies, as you might have to wait for compute to become available before processing a request, and needs more sophisticated infrastructure. Assuming this is built, the conclusion is that a batching cloud that leans on cheaper GPUs can deliver 40–65% cheaper tokens while sticking to relaxed SLAs.

What about *real* models that someone might use. Like GPT-OSS-120B or Qwen3-235B? For low-latency inference you need:
- Scale-up: large available memory per device (think B200).
- Scale-out: high-bandwidth fabrics (NVLink, InfiniBand) for tensor or expert parallelism.
Many GPUs, including data-center staples like L40s, lack the interconnect story to scale out. That’s why lower-end cards are rarely considered for big models.
The workaround is pipeline parallelism:
- Shard the model by layers across many cheaper GPUs (e.g., 5090s with fast FP4 support).
- Keep each GPU busy by streaming different tokens through the pipeline concurrently.
- Unlike tensor/expert parallelism (which speeds up one request), pipeline parallelism speeds up lots of simultaneous requests - perfect for batching.
- With adequate interconnect to overlap activation transfers and compute, you can hit the same throughput targets as NVLink clusters, but on hardware that costs far less.
Batched workloads unlock a different optimization space. If you’re willing to trade latency for price, today’s hardware landscape offers three powerful moves:
1. Use scheduling tricks (priority queues, spot instances) to ride out demand spikes on existing infrastructure.
2. Lean into decode-heavy benchmarks and pick GPUs with the best bandwidth per dollar - even if that means consumer cards.
3. For giant models, pair cheaper GPUs with pipeline parallelism to eke out throughput without enterprise interconnects.
These early results suggest a batching cloud can serve high-volume, tolerance-heavy jobs at a fraction of flagship costs. There’s more engineering ahead - better SLA-aware queues, faster model warm-up, smarter pipeline tooling - but the path toward cheaper tokens is visible.


We work with enterprises at every stage of their self-hosting journey - whether you're deploying your first model in an on-prem environment or scaling dozens of fine-tuned, domain-specific models across a hybrid, multi-cloud setup. Doubleword is here to help you do it faster, easier, and with confidence.
