Deep Learning Glossary
Top P, also known as nucleus sampling, is a method used in large language models (LLMs) to select a subset of possible next tokens where the cumulative probability exceeds a specified threshold 'P'. By sampling from this subset, it ensures a balance between randomness and predictability in a model's outputs. This method offers more dynamic sampling than top K and can lead to more varied and high-quality generated content.
Related Articles
Deep learning models are trained on data. During the training process, the training data is passed through the model, and the model is updated to attempt better performance in a task on said training data. For example, for generative NLP models, the training task is (usually) to predict the next word (properly, tokens), given all of the previous words. The goal is the model, at inference time, is able to generalise beyond the information encoded in its training data to unseen test data.
Related Articles
The training set is simply the training data used to train a model.
Related Articles
Transfer learning is an attempt to reuse concepts which have been previosuly encoded in a machine learning model for a new task. For example, in machine learning training, often two phases are involved: one pretraining, where the model picks up general information, and finetuning, where the model learns domain specific knowledge. General world knowledge is transferred from the first stage to the second. (see pretraining, finetuning).
Related Articles
A transformer is a particular architecture of deep learning networks used for language, image, and audio modelling. There are many variants but most transformer models involve alternating fully-connected and attention-based layers.
Related Articles
Conceived by Alan Turing in 1950, the Turing Test is a test of a machine's ability to exhibit intelligent behaviour indistinguishable from, that of a human.
Related Articles
Unsupervised learning is machine learning where the training process does not include data labelled by a supervisor. Instead, the model is trained to extract insights from the statistical structure of the raw data. A typical example of a task possibly solvable via unsupervised learning is that of clustering.
Related Articles
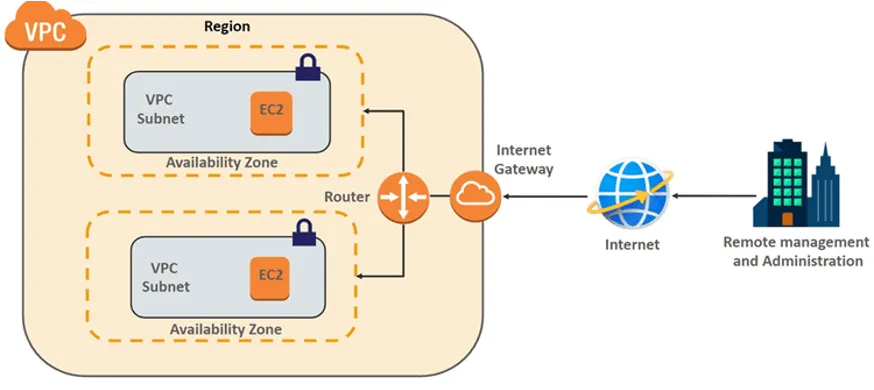
A Virtual Private Cloud (VPC) is an isolated, private section within a public cloud that allows organizations to run their cloud resources in a secure and secluded environment. It provides configurable IP address ranges, subnets, and security settings, enabling users to closely manage networking and security, similar to a traditional data center but with the scalability and flexibility of the cloud.
Related Articles
The weights of a language model are the values which are used to calculate the outputs of the model. These are what are optimized during training.
Related Articles
Zero shot learning is the ability of a model to generalize to unseen inputs without any additional information being passed to them. It is in comparison to one shot learning and few shot learning.
Related Articles