Inference, for
Every Use Case
Optimized high performance inference that meets the demands of your business.

Inference at Scale
Inference large scale jobs for a fraction of the cost of other inference providers. Doubleword Batch is an inference stack built from the ground up specifically for batch workloads - optimizing hardware, runtime, and orchestration exclusively for cost efficiency and reliability.
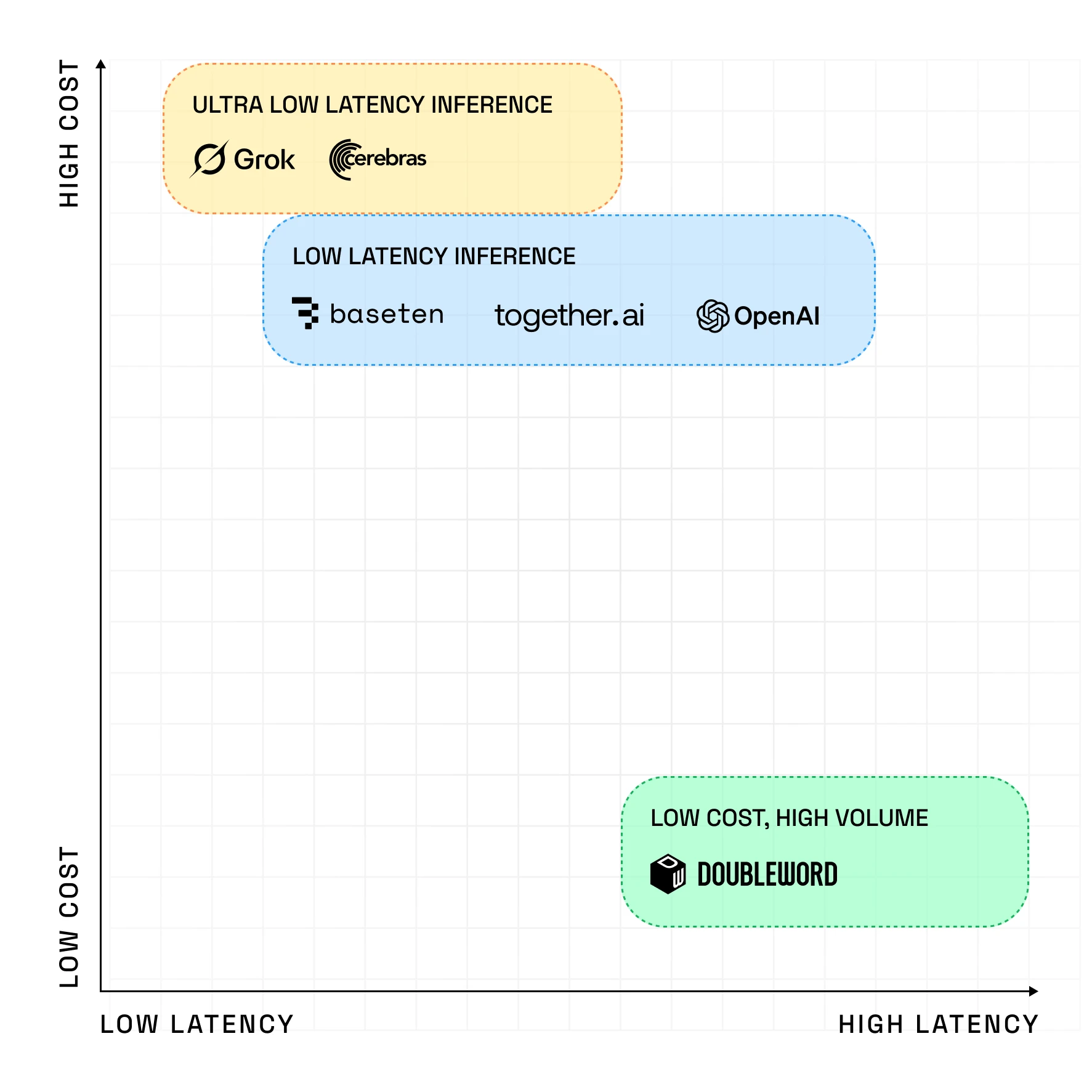
Manage Inference across your business
Stay in control of every model, deployment, and API - across teams, jurisdictions and clouds. The Doubleword control layer gives you centralised visibility and governance across all AI usage - both your private deployments and cloud APIs like OpenAI and Bedrock. With built-in auth, RBAC, intelligent logging, and usage metering, your teams stay compliant and secure.
Inference in your private environment
Run open-source and custom language models at scale, in your private cloud, on-prem, or hybrid infrastructure for your most sensitive use cases.
Deployed as infrastructure-as-code, we pair state of the art inference engines with our custom-built scaling layer to create scalable OpenAl compatible APIs within your environment.
Our customers focus on Delivering Value, not managing infrastructure
.png)





Stop overpaying for inference.
The Doubleword Batch private preview is ideal for teams running batch or async inference - workloads where a 1-hour or 24-hour SLA works. Reserve your spot today - with free credits to get started - you don't want to miss out.
